OS:ubuntu 10.04
Hadoop version: 0.22.0
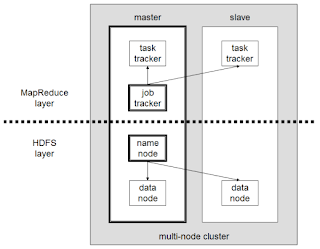
A small Hadoop cluster will include a single master and multiple worker nodes. But here I am using two machines, one for master and other for slave. The master node consists of a JobTracker, TaskTracker, NameNode, and DataNode.A slave acts as both a DataNode and TaskTracker.
I assigned the IP address 192.168.0.1 to the master machine and 192.168.0.2 to the slave machine.
Step 1: Install oracle jdk
Follow this step on both master and slave.
Add the repository to your apt-get:
$sudo apt-get install python-software-properties
$sudo add-apt-repository ppa:sun-java-community-team/sun-java6
Update the source list
$sudo apt-get update
Install sun-java6-jdk
$ sudo apt-get install sun-java6-jdk
Select Sun’s Java as the default on your machine.
$ sudo update-java-alternatives -s java-6-sun
After the installation check the java version using
hadooptest@hadooptest-VM$java -version
java version "1.6.0_20"
Java(TM) SE Runtime Environment (build 1.6.0_20-b02)
Java HotSpot(TM) Client VM (build 16.3-b01, mixed mode, sharing)
Part 2: Configure the networkYou must change the /etc/hosts file with the details of the master and slave IP. Open /etc/hosts file in both master and slave using.
$sudo vi /etc/hosts
And add the following lines
192.168.0.1 master
192.168.0.2 slave
Part 3: Create hadoop user
In this step, we will create a new user and group in master and slave to run the hadoop. Here I added user 'hduser' with in the group 'hd' using following commands.
$sudo addgroup hd
$sudo adduser --ingroup hd hduser
Part 4: SSH Setup
Install ssh on master and slave using
$sudo apt-get install ssh
Let’s configure password less shh between master and slave.
$ su - hduser
$ssh-keygen -t rsa -P ""
$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
On the Master machine run the following
$hduser@master:~$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub hduser@slave
Test the ssh configuration on master :
$ ssh master
$ ssh slave
If the ssh configuration is correct. the above command does nor ask for password.
Part 5: Configuring Hadoop
(Run this step on master and slave as normal user)
Download the latest hadoop 0.22 from: http://www.reverse.net/pub/apache//hadoop/common/ and extract it using :
Hadoop: tar -xvf hadoop*.tar.gz
Move hadoop folder from downloaded folder to /usr/local
$sudo mv /home/user/Download/hadoop /usr/local/
Change the ownership of the hadoop directory
$sudo chown -R hduser:hd /usr/local/hadoop
Configure /home/hduser/.bashrc with the Hadoop variables enter the following commands:
$ sudo vi /home/hduser/.bashrc
Add the following lines to the end
export JAVA_HOME=/usr/lib/jvm/java-6-sun
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
Create a folder which Hadoop will use to store its data file
$sudo mkdir -p /app/hadoop/tmp
$sudo chown hduser:hd /app/hadoop/tmp
Open the core-site.xml file in hadoop configuration directiory(/usr/local/hadoop/conf)
$sudo vi /usr/local/hadoop/conf/core-site.xml
Add the following property tags between
and tag in core-site.xml:
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>Temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:54310</value>
<description>Default file system.</description>
</property>
Open the mapred-site.xml file in hadoop configuration directory
$sudo vi /usr/local/hadoop/conf/mapred-site.xml
Add the following property tags to mapred-site.xml:
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
<description>MapReduce job tracker.</description>
</property>
Open the hdfs-site.xml file in hadoop configuration directory
$sudo vi /usr/local/hadoop/conf/hdfs-site.xml
Add the following property tags to hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
Open the hadoop-env.sh file in hadoop configuration directory
$sudo vi /usr/local/hadoop/conf/hadoop-env.sh
Add uncomment the following line with proper java path
export JAVA_HOME=/usr/lib/jvm/java-6-sun
Part 6: Configure Master Slave Settings
Edit the following files on both the master and slave machines.
conf/masters
conf/slaves
On Master machine:
Open the following file: conf/masters and change ‘localhost’ to ‘master’:
master
Open the following file: conf/slaves and change ‘localhost’ to
master
slave
On the Slave machine:
Open the following file: conf/masters and change ‘locahost’ to ‘slave’:
slave
Open the following file: conf/slaves and change ‘localhost’ to ‘slave’
slave
Part 7 : Starting Hadoop
To format hdaoop datanode, run the following on master in hadoop/bin(/usr/local/hadoop/bin):
$ hadoop namenode -format
Start HDFS daemons, run the following command in hadoop/bin:
$./start-dfs.sh
Run jps command on master, got output like this
14399 NameNode
16244 DataNode
16312 SecondaryNameNode
12215 Jps
Run jps command on slave,got output like this
11501 DataNode
11612 Jps
To Start Map Reduce daemons, run the following command in hadoop/bin
$./start-mapred.sh
Run jps command on master
14399 NameNode
16244 DataNode
16312 SecondaryNameNode
18215 Jps
17102 JobTracker
17211 TaskTracker
Run jps command on slave
11501 DataNode
11712 Jps
11695 TaskTracker
Part 8:Example MapReduce job using word count
Download Plain Text UTF-8 encoding file for following books and store into a local directory (here using /home/hadoopmaster/gutenberg)
Download mapreduce programme jar(
hadoop-examples-0.20.203.0.jar) file to any local folder (here using /home/hadoopmaster).
To run mapreduce programe, we need to copy these files into HDFS directory from local directory. For this purpose, first login to the hadoop user and move hadoop directory
$su hduser
$cd /usr/local/hadoop/
Copy local file to HDFS using
$hadoop dfs -copyFromLocal /home/hadoopmaster/gutenberg /user/hduser/gutenberg
Check the content inside HDFS directory using
$hadoop dfs -ls /user/hduser/gutenberg
Move to folder that containing downloaded jar file.
Run the following command to execute the programme
$hadoop jar /home/hadoop-master/hadoop-examples-0.20.203.0.jar wordcount
/user/hduser/gutenberg /user/hduser/gutenberg-out
Here /user/hduser/gutenberg is the input directory and /user/hduser/gutenberg-out is the output directory. Both input and output directory must be in HDFS file system. The jar file should be in local file system
It will take some time according to your system configuration. You can track the job progress using hadoop tracker websites
JobTracker website: http://master:50030/
NameNode website : http://master:50070/
Task track website: http://master:50060/
Check the result of the programme using
$hadoop dfs -cat /user/hduser/gutenberg-output/part-r-00000
